Enzyme engineering
To achieve success in enzyme discovery and optimization, it's essential to have a multifaceted approach that encompasses diversity, screening capacity, and robust analytical capabilities. The journey begins with the ability to diversify effectively, ensuring a broad exploration of potential candidates. This diversity is crucial for uncovering novel enzymes or optimal starting points for evolutionary campaigns. Equally important is having a high-throughput screening capacity with low coefficient of variation (CV), which ensures consistent and reliable results across tests. This screening capability must be paired with advanced next-generation sequencing (NGS) techniques, allowing for the comprehensive sequencing data.
Our success is amplified by the powerful analytical algorithms we employ, which are adept at correlating genotype with phenotype. These algorithms are designed to detect even the smallest signals, ensuring that no potential candidate is overlooked. The ability to accurately map these relationships enables us to navigate the phenotypic landscape effectively, aiming to reach an optimal point where the enzyme exhibits its best performance. Success in this field compounds over time, as each discovery builds upon the last, creating a momentum that drives continuous improvement and innovation. By integrating these diverse elements, we ensure a systematic and thorough approach to enzyme optimization, decreasing the timeline of the project to its minimum.
We create genotype-phenotype maps that drive optimization.
- We use next-generation sequencing (NGS) to genotype EVERYTHING, whereas others only focus on the top hits.
- We've invested heavily in building a high-throughput operation with advanced analytical equipment.
- Taken together, we can create a detailed genotype-phenotype map, enabling our AI algorithms to learn from all the data and accelerate progress.
Example result
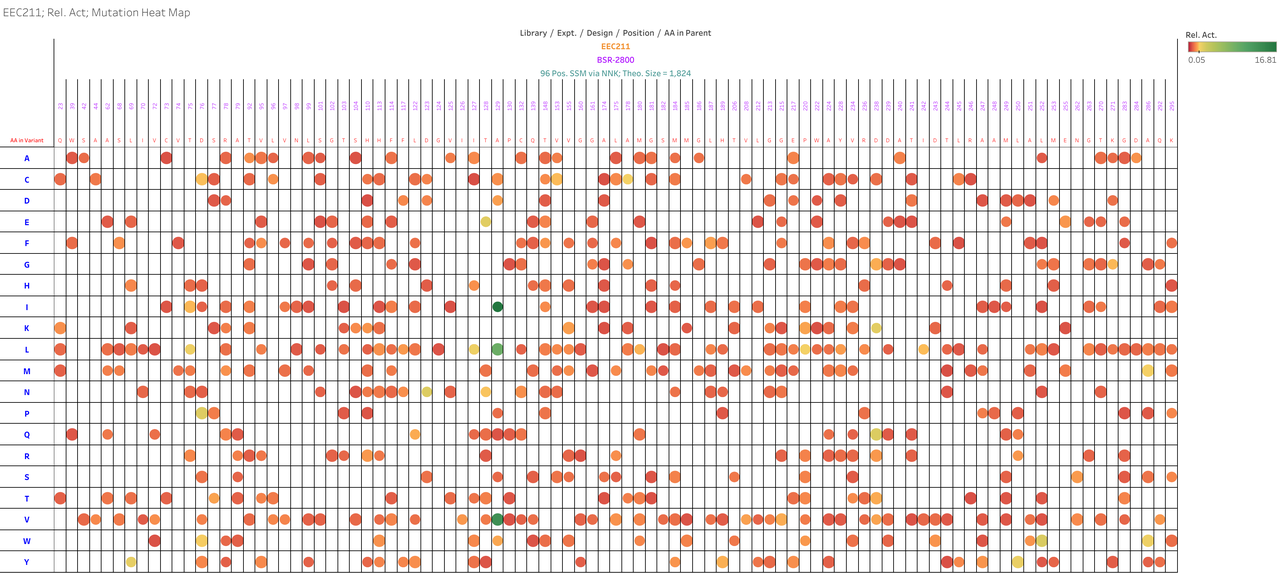
Above you can see an example of a beautiful and dense genotype-phenotype map aimed at improving the Relative Activity (Rel. Act.) of an enzyme. We subjected ninety-six positions to Site Saturation Mutagenesis (SSM), and the data shows that mutations at position 129 are quite significant! Our AI algorithms are excellent at detecting subtler trends, especially when hotspot mutations are combined. We're here to help you every step of the way!
Take a small step!
Purchase our mutant library plates and get to know us. We can then provide further support to help you overcome screening capacity limitations, building a relationship and going on a journey together with our modeling and algorithmic services. In the conversation around Protein AI, many are still relying on the same tired datasets for model validation, limiting the potential for groundbreaking discoveries. We see this clearly and are committed to providing a robust data generation engine that fuels real innovation.